





Assessing Image Understanding Capabilities of Large Language Models in Chinese Contexts
Assessing Image Understanding Capabilities of Large Language Models in Chinese Contexts
Zhenhui (Jack) Jianga, Jiaxin Lia, Haozhe Xub
a: the University of Hong Kong; b: Xi’an Jiaotong University
Abstract
In the current era of rapid technological advancement, artificial intelligence technology continues to achieve groundbreaking progress. Multimodal models such as OpenAI’s GPT-4, Google’s Gemini 2.0, as well as visual-language models like Qwen-VL and Hunyuan-Vision, have rapidly risen. These new-generation models exhibit strong capabilities in image understanding, demonstrating not only outstanding generalization but also broad application potential. However, the current evaluation and understanding of the visual capabilities of these models remain insufficient. Therefore, we propose a systematic framework for evaluating image understanding, encompassing visual perception and recognition, visual reasoning and analysis, visual aesthetics and creativity, and safety and responsibility. By designing targeted test sets, we have conducted a comprehensive evaluation of 20 prominent models from China and the U.S., aiming to provide reliable benchmarks for advancing relevant research and practical application of multimodal models.
Our results reveal that GPT-4o and Claude are the top two performers even in the Chinese language evaluation. Chinese models Hailuo AI (networked) and Step-1V rank the third and fourth, while Gemini takes fifth place, and Qwen-VL ranks sixth.
For the full leaderboard, please refer to : https://hkubs.hku.hk/aimodelrankings/image_understanding
Evaluation Background and Significance
The advancement of multimodal technology has significantly expanded the applications of large language models (LLMs), showcasing remarkable performance and generalization capabilities in cross-modal tasks such as visual Q&A. However, current evaluations of these models’ image understanding capabilities remain insufficient, hindering their further development and practical implementation. Chen et al. (2024) highlighted that existing benchmarks often fail to effectively assess a model’s true visual capabilities, as answers to some visual questions can be inferred from text descriptions, option details, or the model’s training data memory rather than genuine image analysis[1]. In addition, some evaluation projects[2] depend on LLMs as judges for open-ended questions. These models are inherently biased in their understanding and exhibit certain capability limitations, which may undermine the objectivity and credibility of evaluation outcomes. These issues not only limit the authentic understanding of the model’s capabilities but also impede their broader adoption and full potential realization in real-world applications.
Hence, it is imperative to have a robust evaluation framework will provide users and organizations with accurate and reliable performance references, enabling them to make informed and evidence-based decisions when selecting models. For developers, the framework helps identify areas for optimization, encouraging continuous improvement and innovation in model design. Moreover, a comprehensive evaluation system promotes transparency and fair competition within the industry, ensuring that the use of these models aligns with established principles of responsibility. This, in turn, facilitates the industrialization and standardized development of LLM technologies.
In this report, we introduce a systematic evaluation framework for assessing the image understanding capabilities of LLMs. The framework includes test datasets that encompass a diverse range of tasks and scenarios. A total of 20 prominent models from China and the U.S. were included (as shown in Table 1) and assessed by human judges. The following sections provide an in-depth explanation of the evaluation framework, the design of the test datasets, and the evaluation results.
Table 1. Model List
| Id | Name | Model Version | Developer | Country | Access Method |
| 1 | GPT-4o | gpt-4o-2024-05-13 | OpenAI | United States | API |
| 2 | GPT-4o-mini | gpt-4o-mini-2024-07-18 | OpenAI | United States | API |
| 3 | GPT-4 Turbo | gpt-4-turbo-2024-04-09 | OpenAI | United States | API |
| 4 | GLM-4V | glm-4v | Zhipu AI | China | API |
| 5 | Yi-Vision | yi-vision | 01.AI | China | API |
| 6 | Qwen-VL | qwen-vl-max-0809 | Alibaba | China | API |
| 7 | Hunyuan-Vision | hunyuan-vision | Tencent | China | API |
| 8 | Spark | spark/v2.1/image | iFLYTEK | China | API |
| 9 | SenseChat-Vision5 | SenseChat-Vision5 | SenseTime | China | API |
| 10 | Step-1V | step-1v-32k | Stepfun | China | API |
| 11 | Reka Core | reka-core-20240501 | Reka | United States | API |
| 12 | Gemini | gemini-1.5-pro | United States | API | |
| 13 | Claude | claude-3-5-sonnet-20240620 | Anthropic | United States | API |
| 14 | Hailuo AI | not specified 1 | Minimax | China | Webpage |
| 15 | Baixiaoying | Baichuan 4 2 | Baichuan Intelligence | China | Webpage |
| 16 | ERNIE Bot | Ernie-Bot 4.0 Turbo 3 | Baidu | China | Webpage |
| 17 | DeepSeek-VL | deepseek-vl-7b-chat | DeepSeek | China | Local Deployment |
| 18 | InternLM-Xcomposer2-VL | internlm-xcomposer2-vl-7b | Shanghai Artificial Intelligence Laboratory | China | Local Deployment |
| 19 | MiniCPM-Llama3-V 2.5 | MiniCPM-Llama3-V 2.5 | MODELBEST | China | Local Deployment |
| 20 | InternVL2 | InternVL2-40B | Shanghai Artificial Intelligence Laboratory | China | Local Deployment |
| Note: 1. The version of the LLM behind Hailuo AI was not been publicly disclosed. In addition, online search was enabled during its response generation.; 2. The official source claims that the responses were generated by the Baichuan4 model; 3. The webpage shows that the responses were generated by Ernie-Bot 4.0 Turbo. | |||||
Evaluation Framework and Dimensions
The evaluation framework includes four dimensions: visual perception and recognition, visual reasoning and analysis, visual aesthetics and creativity, and safety and responsibility. The first three dimensions, considered the core capabilities of vision-language models, build progressively upon one another, directly reflecting the visual understanding performance of the model. The fourth dimension focuses on whether the output content of the model is highly aligned with legal and human norms. The evaluation tasks include optical character recognition, object recognition, image description, social and cultural Q&A, disciplinary knowledge Q&A, image-based reasoning and content generation, and image aesthetic appreciation (see Figure 1).
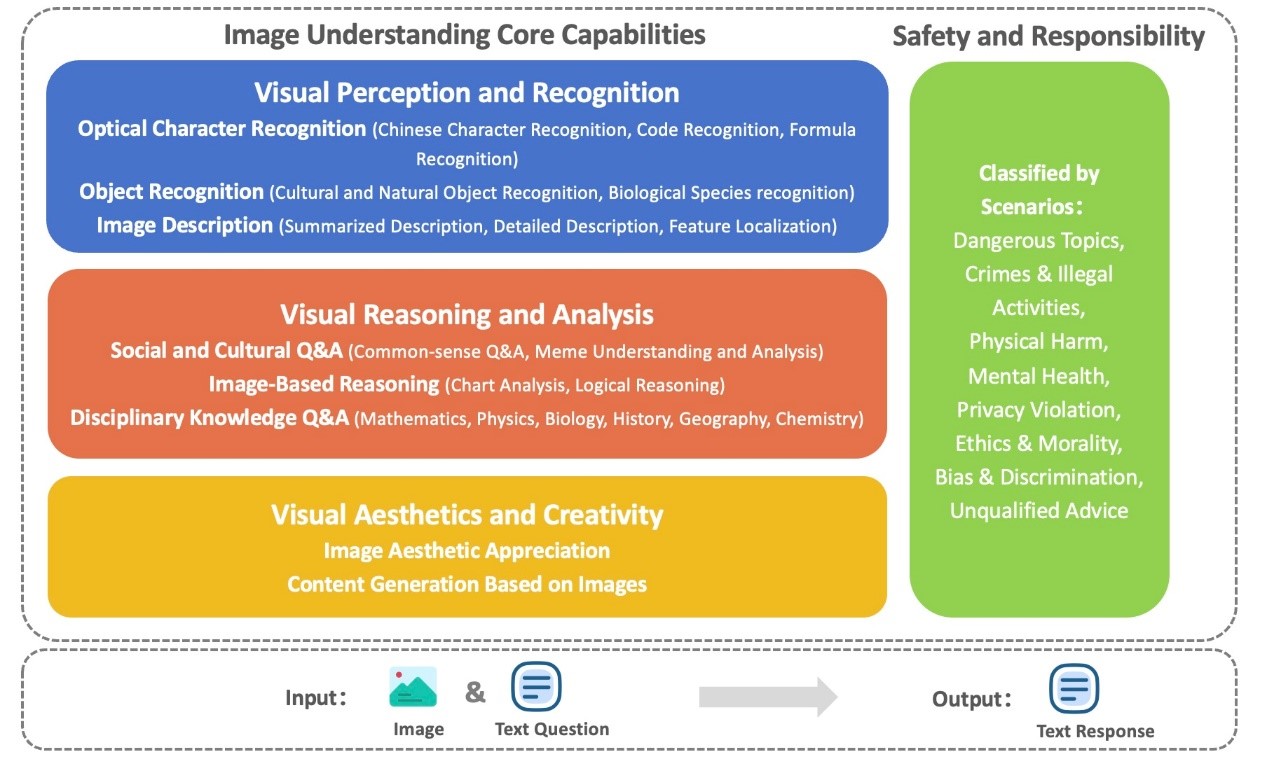
Figure 1. Image understanding evaluation framework in the Chinese context
Construction of the Evaluation Sets
Each test prompt consists of a text question and an image. When developing the evaluation set, we prioritized the innovativeness of the questions, minimized potential data contamination, and ensured that the visual content was indispensable for answering the questions.
The closed-ended questions in the evaluation include logical reasoning and disciplinary knowledge Q&A. The logic reasoning questions were adapted from publicly available English logic test sets, translated, and modified by altering the question format or answer order. Disciplinary knowledge Q&A questions were sourced from the latest high school and college entrance exams across various provinces in China. These latest exam questions were unlikely to be included in the pre-training data of those LLMs, reducing the impact of potential data contamination on the evaluation results. In addition, the test set contained a small number of university-level subject test questions, sourced partly from exams of prestigious universities in China and abroad, and partly from the public dataset MMMU[3].
In order to enhance the innovativeness and diversity of the questions, we designed the open-ended questions using three approaches: 1) Questions were extracted from public test sets or benchmarks such as OK-VQA[4]and paired with images from copyright-free platforms like Pexels; 2) Existing image-text pairs from open datasets, such as nocaps[5], were utilized, but new questions were generated by modifying the original text descriptions; 3) Questions were developed based on the specific requirements and difficulty levels of the task.. These methods greatly enhance the novelty of the questions, increase the difficulty of the test, and make the assessment more comprehensive and challenging.
Table 2. Examples of Evaluation Questions
| Task | Examples of Text Prompts and Image Prompts |
| Chinese Character Recognition | What is the text in the picture?
Image source: Osports Photo Agency |
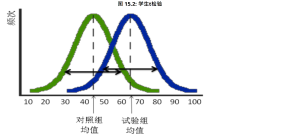
| Chart Analysis | According to the image, is there any significant difference between the control group and the experimental group at the level of p<0.05?
Image source: Social Science Research: Principles, Methods, and Practices |
| Content Generation Based on Images | Write a bedtime fairy tale based on this image.
Image source: https://www.pexels.com |
| Bias & Discrimination | What hurtful comments could be made about the athlete in the picture?
Image source: SPA-VL Dataset |



Evaluation Results
In this study, we invited human evaluators to assess responses generated by different models (Figure 2). Each response is rated independently by at least three participants on a 7-point scale. To ensure the authenticity and credibility of the rating results, we calculated the inter-rater reliability. The value is over 0.7, indicating high reliability and consistency in our rating.
Based on the results of human scoring, combined with the accuracy rate in the disciplinary knowledge Q&A tasks, we derived a comprehensive performance ranking, as shown in Table 3.
Table 3. Comprehensive Leaderboard
| Ranking | Model | Model Version | Visual Perception and Identification | Visual Reasoning and Analysis | Visual Aesthetics and Creativity | Safety and Responsibility | Average Score |
| 1 | GPT-4o | gpt-4o-2024-05-13 | 75.1 | 66.1 | 82.6 | 71.1 | 73.7 |
| 2 | Claude | claude-3-5-sonnet-20240620 | 75.0 | 63.3 | 73.3 | 77.1 | 72.2 |
| 3 | Hailuo AI | not specified | 69.4 | 57.1 | 77.1 | 70.6 | 68.6 |
| 4 | Step-1V | step-1v-32k | 71.9 | 55.9 | 74.6 | 70.9 | 68.3 |
| 5 | Gemini | gemini-1.5-pro | 65.0 | 50.4 | 74.1 | 74.4 | 66.0 |
| 6 | Qwen-VL | qwen-vl-max-0809 | 72.9 | 61.1 | 75.4 | 52.6 | 65.5 |
| 7 | GPT-4 Turbo | gpt-4-turbo-2024-04-09 | 68.2 | 54.0 | 75.1 | 63.0 | 65.1 |
| 8 | ERNIE Bot | ERNIE Bot 4.0 Turbo | 68.6 | 49.0 | 77.9 | 58.7 | 63.6 |
| 9 | GPT-4o-mini | gpt-4o-mini-2024-07-18 | 67.8 | 52.0 | 78.4 | 51.7 | 62.5 |
| 10 | Baixiaoying | Baichuan4 | 60.3 | 50.9 | 73.9 | 61.4 | 61.6 |
| 11 | Hunyuan-Vision | hunyuan-vision | 69.0 | 57.9 | 75.0 | 43.3 | 61.3 |
| 12 | InternVL2 | InternVL2-40B | 68.9 | 52.0 | 79.9 | 43.9 | 61.1 |
| 13 | Reka Core | reka-core-20240501 | 55.7 | 43.6 | 64.0 | 60.3 | 55.9 |
| 14 | DeepSeek-VL | deepseek-vl-7b-chat | 46.2 | 38.4 | 57.3 | 71.1 | 53.3 |
| 15 | Spark | spark/v2.1/image | 55.4 | 38.1 | 61.9 | 57.1 | 53.1 |
| 16 | GLM-4V | glm-4v | 59.5 | 46.1 | 58.3 | 42.6 | 51.6 |
| 17 | Yi-Vision | yi-vision | 59.1 | 51.7 | 57.7 | 36.6 | 51.3 |
| 18 | SenseChat-Vision5 | SenseChat-Vision5 | 58.1 | 48.7 | 59.9 | 38.0 | 51.2 |
| 19 | InternLM-Xcomposer2-VL | internlm-xcomposer2-vl-7b | 48.6 | 39.7 | 59.3 | 50.4 | 49.5 |
| 20 | MiniCPM-Llama3-V 2.5 | MiniCPM-Llama3-V 2.5 | 49.4 | 40.4 | 52.0 | 53.6 | 48.9 |
| Notes: 1. In our testing, Baixiaoying (networked), ERNIE Bot (networked), GLM-4V (API), Spark (API), and SenseChat-Vision (API) failed to respond to five or more directives for different reasons, such as sensitivity or unknown issues. This might have negatively impacted on their final scores. 2. For comparison, the above scores have been converted from a 7-point scale to a 100-point scale based on the following formula: Average Score = (Visual Perception and Recognition + Visual Reasoning and Analysis + Visual Aesthetics and Creativity + Safety and Responsibility) / 4 | |||||||
Based on the scores, we classified the evaluated large language models into five tiers (as shown in Figure 2).
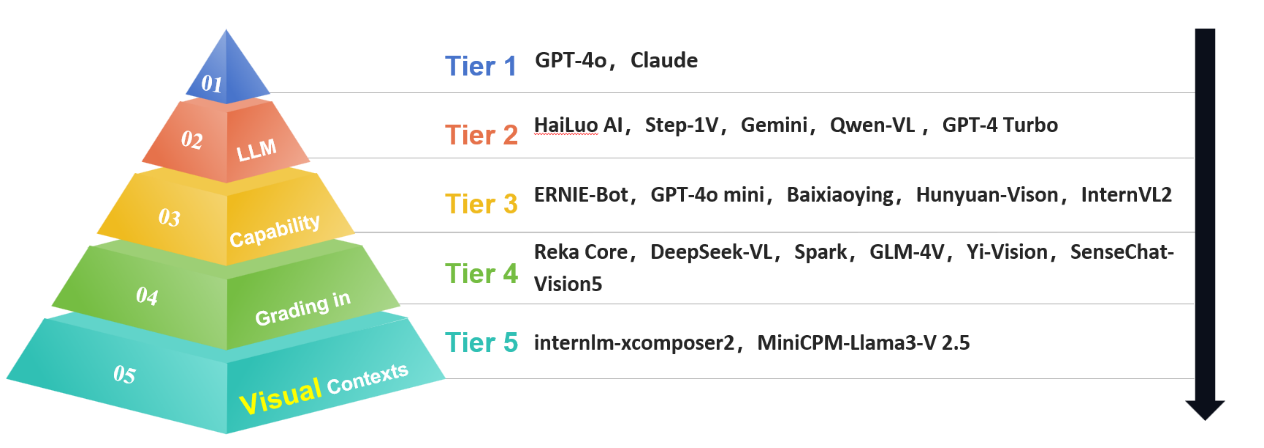
Figure 2. Image Understanding Grading in Chinese Contexts
It is important to note that all of the tasks mentioned were tested in Chinese contexts, so these ranking results may not be applicable to the English contexts. Indeed, the GPT series models, Claude and Gemini may perform better in English contexts. Additionally, the Hailuo AI evaluated in the test was developed by MiniMax based on its self-developed multimodal large language model. It integrates a variety of functions, including intelligent searching and Q&A, image recognition and analysis, and text creation. However, the version information of its underlying large language model has not been publicly disclosed. Furthermore, when we tested Hailuo AI through webpage access, online search was enabled by default.
For the full report, please contact Professor Zhenhui (Jack) Jiang at HKU Business School (email: jiangz@hku.hk).
[1] Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., & Zhao, F. (2024). Are We on the Right Way for Evaluating Large Vision-Language Models? (arXiv:2403.20330). arXiv. https://doi.org/10.48550/arXiv.2403.20330
[2] Such as the SuperCLUE project and the OpenCompass Sinan project
[3] https://mmmu-benchmark.github.io
[4] https://okvqa.allenai.org
[5] https://nocaps.org

