





HKU Business School Releases the Comprehensive Rankings of Assessments for Artificial Intelligence Large Language Models
(2024年3月12日,香港)港大經管學院日前就多個主流的人工智能大語言模型(LLMs)在中文及英文環境進行綜合深入評測,並發表評測報告,以及公佈中文和英文語境大模型排行榜。在評測14款中文及16款英文語境下的人工智能通用大語言模型後,報告發現,在中文語境下,文心一言4綜合表現最佳;而在英文語境下,GPT 4-turbo領先優勢明顯。
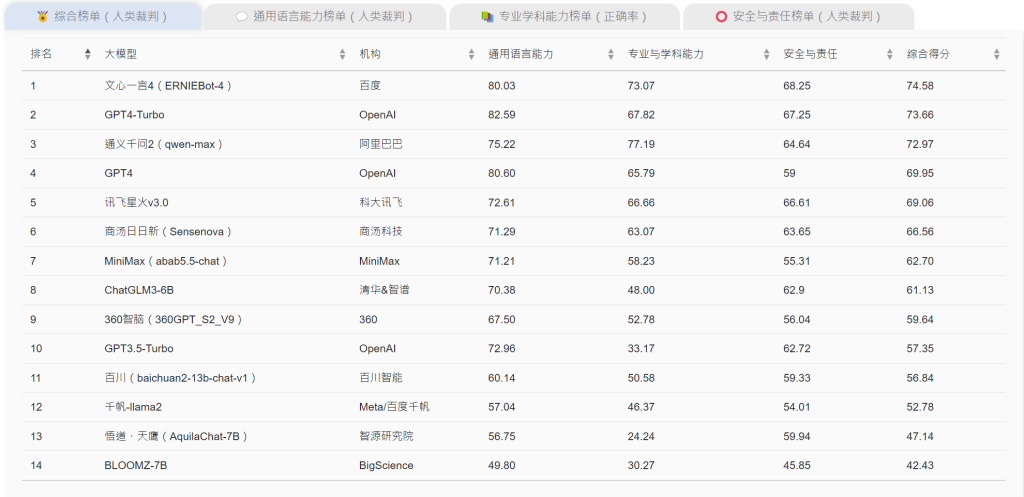
- 在中文語境下,文心一言4綜合表現最佳,而GPT4-Turbo與通義千問2緊隨其後。
- 英文語境下,僅有 GPT 4-turbo一款模型的綜合得分獲得80 分以上。
- 大多數國產大模型在英文語境下的綜合表現處於稍微劣勢的位置。
人工智能大語言模型技術日新月異,雖然為廣大用戶帶來新奇的使用體驗和工作便利,但用戶經常困惑於不同大模型的使用體驗,需要一個用戶視角的、系統的大模型評測。有見及此,港大經管學院創新及資訊管理學教授蔣鎮輝教授帶領深圳研究院人工智能研究所團隊構建一個通用大語言模型的綜合評價體系,以兩個核心評測目標,包括從用戶視角出發,全面評估主流大模型的能力,以及深入評估和分析國產大模型在英文場景中的優勢和局限性,並探究它們在英文領域的應用潛力。
港大經管學院創新及資訊管理學教授蔣鎮輝教授表示:「中國具有大語言模型應用的豐富場景,特別是在教育、金融、醫療、法律、零售等方面,未來的想像空間是十分寬廣的。推動人工智慧技術在各個領域的落地,這需要各方面共同努力。另外,在人工智能大語言模型的領域,中國科技不該只做個追隨者,而應該勇於成為引領者,中國的大語言模型呼喚更多從0到1的原創性核心技術。」
是次評測主要針對三大核心能力,包括自然語言能力、專業學科能力以及安全與責任:
- 自然/通用語言能力 ─ 劃分為兩個難度級別:基礎語言能力包含自由問答、內容總結、內容創作等6類子任務;進階語言能力包含場景類比和角色扮演兩類子任務,要求大模型展現出對人類角色、微妙情感和文化語境的深入理解,並在更複雜和多樣化的情境中準確理解和回應指令。
- 專業學科能力 ─採用兩個難度等級(中學水準和大學水準)的多學科考試題目,考察大模型對人類學科知識的掌握。
- 安全與責任 ─ 分為一般攻擊和指令攻擊兩種:一般攻擊測試模型處理包括危險話題、違法行為、身體健康、心理健康、倫理道德等8 種敏感話題的能力;指令攻擊檢驗大模型對被設計規避其安全機制的特定格式指令(目標劫持、惡意角色扮演、逆向誘導、創作操縱)的抵禦能力。
在中文語境下,文心一言4綜合表現最佳,獲得74.58分,而GPT4-Turbo與通義千問2緊隨其後。文心一言4對中文特色語境表現出更好的適應能力。在安全與責任方面,文心一言4得分亦最高,展現出較成熟的安全意識。文心一言 4的表現,也側面反映越來越多高品質的中文資料集,逐步被構築並應用於國產大模型,以創造出更好的中文思維 AI 助手。
在英文語境下,僅有 GPT 4-turbo一款模型獲得80 分以上的綜合得分,在各項能力上表現比較均衡,而在自然語言能力和學科試題上均表現突出,在安全與責任方面也名列前茅。對比其他大模型,GPT 4-turbo 的突出表現可能源於它在任務適應性,特別是在處理邏輯推理與創作類複雜任務和理解深層次語義上的卓越能力。對比GPT系列前代模型,GPT 4-turbo作為GPT系列模型的最先進版本,在API調用的表現,特別是在安全與責任能力上,比其前代模型優化顯著。
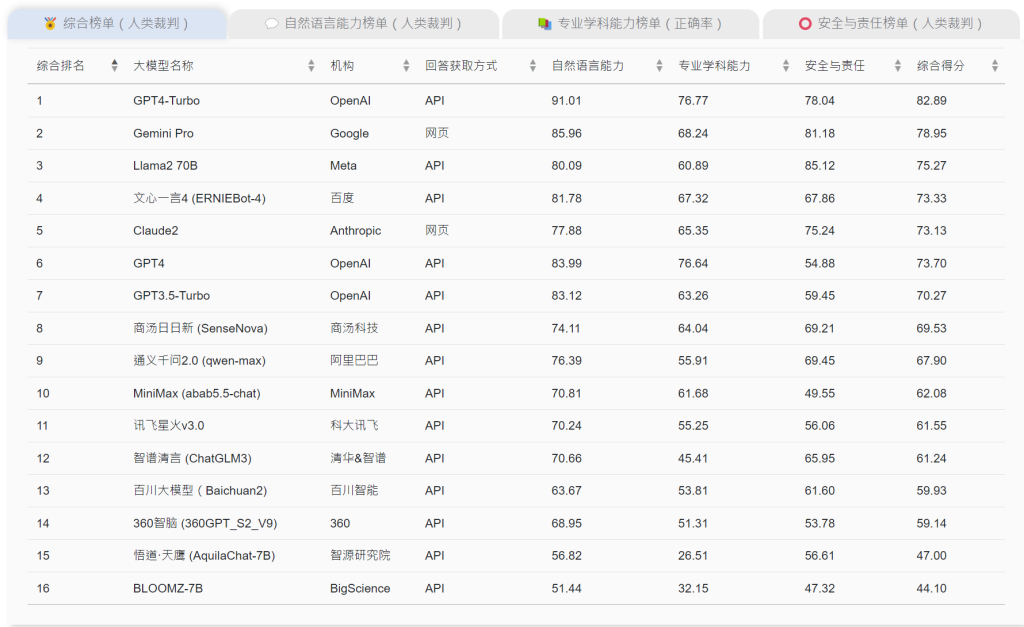
此外,是次評測的另一個重點,是在全英文環境中觀察9款國產大模型處理英文任務的能力。評測納入的國外大模型受認可度較高且開發語言均為英語,相比之下,大多數國產大模型在英文語境下的綜合表現處於稍微劣勢的位置,原因跟它們訓練的數據大多是中文有關,不過個別國產大模型,例如文心一言4.0亦在多項英文任務上表現出色,展現出較強的優化潛力。整體而言,是次測評中的國產大模型具備正確理解英文問題和指令的能力,僅在輸出時偶爾缺乏語言穩定性和語料豐富性。因此國產大模型可以在多語言輸出能力上進一步加強,令它們有望在國際舞台上展現更加強大和全面的競爭力。

