




How to Predict Popularity

If the many functions of digital social media networks could be summed up in one word, it would likely be “sharing”. Through a myriad of apps and platforms, we share our thoughts, feelings, opinions, ideas, and more – with our friends and family, with our online social circles, with strangers, and even with companies.
This ever-growing, non-stop festival of sharing is, in the words of Zhepeng (Lionel) Li from the University of Hong Kong and two co-authors from the University of Arizona and Temple University, creating bridges between “online interactions and offline behaviours”. Their study, What Will Be Popular Next?, focuses on how these bridges affect the popularity of various places and things.
A study of patterns
The research team conducted their work through the lens of social focus theory, essentially looking at patterns in the things that connect people and groups. This study of social networks goes back to the 1980s, long before the advent of digital social media. Social focus theory was designed to examine “a set of connected entities … adopted by a network of social individuals.” These entities are shared affiliations – clubs, parties, films, books; all manner of shared interests – around which people organise their social lives. The entities are called “social foci”, while the people are known as “social actors”.
In basic social networks, the social actors connect with the various social foci and tell other social actors about these foci. This leads to more social actors adopting the foci, making them increasingly popular in a process called “contagious adoption”. Simply put, the more people talk about something, the more popular it becomes – something that has been common in human societies since the dawn of societies themselves.
So it was in the early days of social focus theory. Today, its researchers are obliged to consider the effects of the (relatively) recent phenomenon of digital social networks. Platforms such as Twitter, Facebook, Weibo, and a plethora of others promote “the wide spread of online content among people. Once published, online content [like tweets, posts or videos] spreads [often very quickly] among users through the platforms’ reposting, citing or commenting mechanisms”. Digitisation has turbocharged social networks, leading to a far more broad and rapid spread of social foci than at any point in history. Hence the concept of “going viral” – the almost-overnight spike in the popularity of all kinds of content – clever and funny advertisements, horrific videos of human savagery, memes, political causes, and so on.
Narrowing down the foci
Social focus theory is vast and the options for research topics are many. In this case, the researchers chose to zero in on a single question: “How can information about social networking be leveraged to predict which social foci will be popular in the future?” Put another way, they ask, “How can the popularity of entities be predicted?”
To answer the question, the authors took a fresh look at the concept of social diffusion – the way in which “new ideas and practices spread within and between communities.” In their literature review, they discovered that most research to date has focused on “single-item diffusion, or the adoption of a single independent social focus” – basically looking at how one thing becomes popular. But in the digital world of the 2020s, “multiple social foci can attract the same user base” – i.e. we can be interested in “Everything, Everywhere, All at Once” (you should see that film, if you haven’t). So, the team developed a complex interactive model to predict the popularity ranking of social hotspots – both online and offline.
The potential real-world benefits of these predictions are immense. Take marketing: if marketers and advertisers could have a list of the most popular businesses, it would be both useful and profitable – they could prioritise the right ads for the right audiences, personalise ads better and increase the all-important click-through rate (the percentage of people who click through to a website from an online ad). There are security and retail-related benefits as well, which we will get to later.
A challenging model
So that’s the background. The researchers’ task was then simple and straightforward – just create a mathematical model to measure and predict the popularity of social foci and then sit back and enjoy success, right? No. Not really. Creating such a model involved overcoming a number of major challenges, most of which stem from the fact that people are immensely complicated creatures. For example, people don’t just influence their friends and families towards one social focus, they influence them to “adopt multiple social foci that coexist and compete”. Modelling these behaviours is absolutely not straightforward.
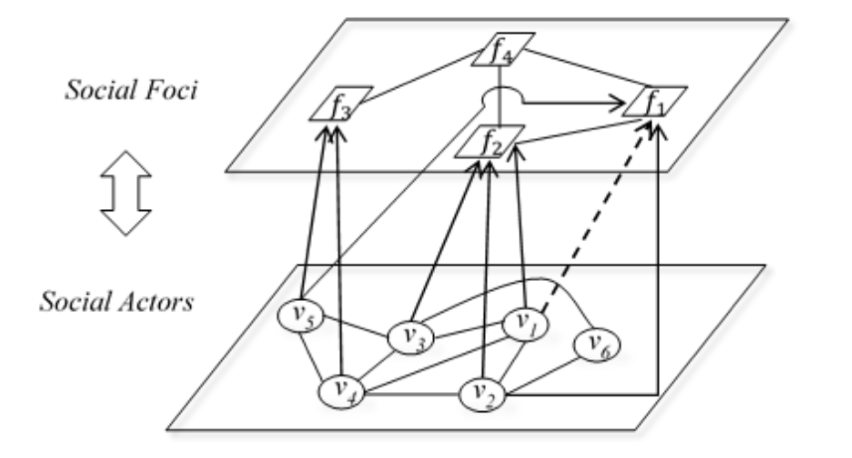
The authors’ model was based on a two-mode social network, pictured above. Such networks show “how individuals, by their agency, create social structures while, at the same time, social structures … constrain and shape the behaviour of the individuals embedded in them.” They theorised that the various interactions and interplays between the social actors and foci actually mean that “peer influences among social actors for adopting social foci and the attractiveness of social foci for engaging social actors are contingent upon each other” – a type of mutual dependency that had not been addressed in earlier studies. Their description of these interactions gives a glimpse into the complexity of their task:
“For example, when social actor ?1 decides whether to adopt social focus ?1, actor ?1 is under the social influence of direct friend ?2 who has visited ?1 . At the same time, ?1 is also influenced by ?2 and ?3 who have both visited ?2, and is also influenced by ?4 and ?5 who have both visited ?3.”
They then used a “bilateral recursive process” (AKA complicated math) to encode the mutual dependencies and produce measurable data, and then devised a machine-learning technique that would produce predictions about ranking popularity.
To test their model, they used three different data sets – two from social network platforms and one from a Canadian bookstore’s mobile platform that lets readers share opinions about the books they read with other users. The digital social networks, one in China and one in the US, had a check-in function enabling users to share their locations with their friends. The social actors were the users and the social foci were the places at which they checked in – restaurants, hotels, stores, and so on. For the bookstore’s platform, the actors were the readers and the books the social foci.
Then began the testing and re-testing phase of their study. Each data set was evaluated by comparing two types of social foci ranking lists – the predicted rank and the true rank. These lists were evaluated using four mathematical metrics which examined different dimensions of performance to provide robust data. These were then evaluated to ensure accuracy and comparison with other methods of benchmarking data.
Skipping ahead to a solid conclusion
This process involved hard work, more complicated math and undoubtedly a number of challenges and changes of approach – par for the course in research studies of this magnitude. With apologies to the researchers, we will skip over this part entirely and instead join them at the happy end of their research journey. They were able to prove that their model not only worked, but that it consistently outperformed other methods. This meant that both their approach and their findings will have useful applications in academia and to different businesses and industries.
In terms of academia, the team proved that previous difficulties in measuring mutual dependency could be overcome by using machine learning in combination with a learning algorithm, something that will prove useful in future studies; as will their finding that just a few key social network characteristics, rather than a large set, are enough to make robust predictions about popularity.
But the real strengths of this study are the practical implications of their findings. Businesses that are associated with a particular social focus “can benefit from knowing their future popularity ranking in advance” – a predicted rise in rankings will give them time to coordinate staff, stock and inventory, while a predicted drop will give them time to plan an advertising campaign or cut costs. Similarly, digital platforms that use location-based services stand to benefit from accurate popularity rankings, helping improve advertising revenue and allowing companies to improve their click-through rate through better targeted ads.
There are also public security benefits. “Identifying hotspot areas where crimes may occur in the future is an effective strategy for allocating police resources”, the authors say. Identifying potential future crime hotspots will allow for “predictive police patrolling”, whereby police resources can be put in place in a particular area ahead of time to ward off any trouble or improve response times.
In a wider sense, knowing what will be popular with various groups of people in different places will be immensely helpful with all manner of jobs, from retail store placement decisions, to point-of-interest recommendations for tourism authorities and businesses, to mobility and access decisions for local governments, and much more.
As human beings, we have a natural tendency to share things with our friends, families and communities. This sharing is often portrayed in a negative light, given its potential for hacking and loss of data privacy, but for studies like Li et al’s, the data we provide is helping to make society safer and more successful – showing that sometimes, sharing can actually be caring.
About this Research
Zhepeng (Lionel) Li, Yong Ge, and Xue Bai (2021). What Will Be Popular Next? Predicting Hotspots in Two-Mode Social Networks. MIS Quarterly 45(2) :925-966
Reference
Borgatti, S.P. 2-Mode Concepts in Social Network Analysis. Encyclopedia of Complexity and System Science. Accessed on 15 June, 2023 at: http://www.analytictech.com/borgatti/papers/2modeconcepts.pdf
Borgatti, S. P., Everett, M. G., 1997. Network analysis of 2-mode data. Social networks 19, 243-269.
Feld, S. L. 1981. The Focused Organization of Social Ties, American Journal of Sociology (86:5), pp. 1015-1035.
Gupta, V., Jung, K., Yoo, S.C. 2020. Exploring the Power of Multimodal Features for Predicting the Popularity of Social Media Image in a Tourist Destination. Multimodal Technol. Interact. 2020, 4(3), 64.
Hanneman, R.A. and Riddle, M. 2005. Introduction to Social Network Methods. Ch. 17. Accessed on 17 June 2023 at: http://faculty.ucr.edu/~hanneman/nettext/
Kennedy, Leslie W., Joel M. Caplan, and Eric Piza. 2011. “Risk Clusters, Hotspots, and Spatial Intelligence: Risk Terrain Modeling as An Algorithm for Police Resource Allocation Strategies,” Journal of Quantitative Criminology (27:3), pp. 339-362.
Opsahl, T. Defining Two-mode Networks. Accessed on 14 June, 2023 at: https://toreopsahl.com/tnet/two-mode-networks/defining-two-mode-networks/
Shang, Y., Zhou, B., Zeng, X., Wang, Y., Yu, H., Zhang, Z. 2022. Predicting the Popularity of Online Content by Modeling the Social Influence and Homophily Features. Phs. Vol 10. 14 July 2022.
Valente, T. W. 1996. Network Models of the Diffusion of Innovations, Computational & Mathematical Organization Theory, (2:2), pp. 163-164.

