





人工智能大语言模型图像理解能力综合评测报告
作者:蒋镇辉a,李佳欣a,徐昊哲b
a: 香港大学经管学院
b: 西安交通大学管理学院
摘要
在科技迅猛发展的当下,人工智能技术不断取得突破性进展,OpenAI的GPT-4o、谷歌的Gemini 2.0这类多模态模型以及通义千问-VL、混元-Vision等视觉语言模型迅速崛起。这些新一代模型在图像理解方面展现出强大的能力,不仅具备出色的泛化性,而且还具有广泛的应用潜力。然而,现阶段对这些模型视觉能力的评估与认知仍存在不足。为此,我们提出了一套全面且系统的图像理解综合评测框架,该框架涵盖视觉感知与识别、视觉推理与分析、视觉审美与创意三大核心能力维度,同时还将安全与责任维度纳入其中。通过设计针对性测试集,我们对20个国内外知名模型进行了全面评估,旨在为多模态模型的研究与实际应用提供可靠参考依据。
我们的研究表明,无论是在图像理解三大核心能力的评估中,还是在包括安全与责任的综合评估中,GPT-4o与Claude的表现都最为突出,位列前二。若仅聚焦于视觉感知与识别、视觉推理与分析、视觉审美与创意三大核心能力维度,国产模型通义千问-VL、海螺AI(联网)与Step-1V依次位列第三、第四、第五,混元-Vision紧随其后。当纳入安全与责任维度进行综合评估时,海螺AI(联网)与Step-1V分别位列第三和第四,Gemini位列第五,通义千问-VL则排名第6。
综合排行榜地址: https://hkubs.hku.hk/aimodelrankings/image_understanding
评测背景与意义
多模态技术的突破为大语言模型带来了卓越的跨模态任务处理能力和广阔的应用前景,然而,当前在模型图像理解能力评估方面仍存在不足,极大制约了多模态模型与视觉语言模型进一步发展和实际落地应用。Chen等人指出,当前评测基准可能无法有效考察模型的视觉理解能力,一些视觉问题的答案可以直接通过文本描述、选项信息或模型对训练数据的记忆得出,无需依赖图像内容[1]。此外,部分评测项目[2]在开放性试题中依赖大语言模型作为裁判,但这些模型本身存在理解偏差,且缺乏真实感知能力,可能影响评测结果的客观性和可信度。这些问题不仅使我们难以全面、准确地洞悉模型的真实能力,还在很大程度上阻碍了模型在实际应用中的推广和价值实现。
因此,科学、系统的评测显得尤为重要。评测不仅能为用户和组织提供精准可靠的性能参考依据,助力其在技术选型过程中做出科学决策,还能为开发者明确优化方向,推动模型的持续改进与创新发展。完善的评测体系更有助于推动行业透明化与公平竞争,幷确保模型的使用符合责任规范,从而促进大模型技术的产业化与规范化发展。
基于此,报告中提出了一套系统的模型图像理解评测框架,开发了覆盖多种任务与场景的测试集,幷通过人类评审对20个国内外知名模型(如表1)进行了综合评估。下文将详细介绍评测框架、测试集设计与测试结果。
表1. 评测模型列表
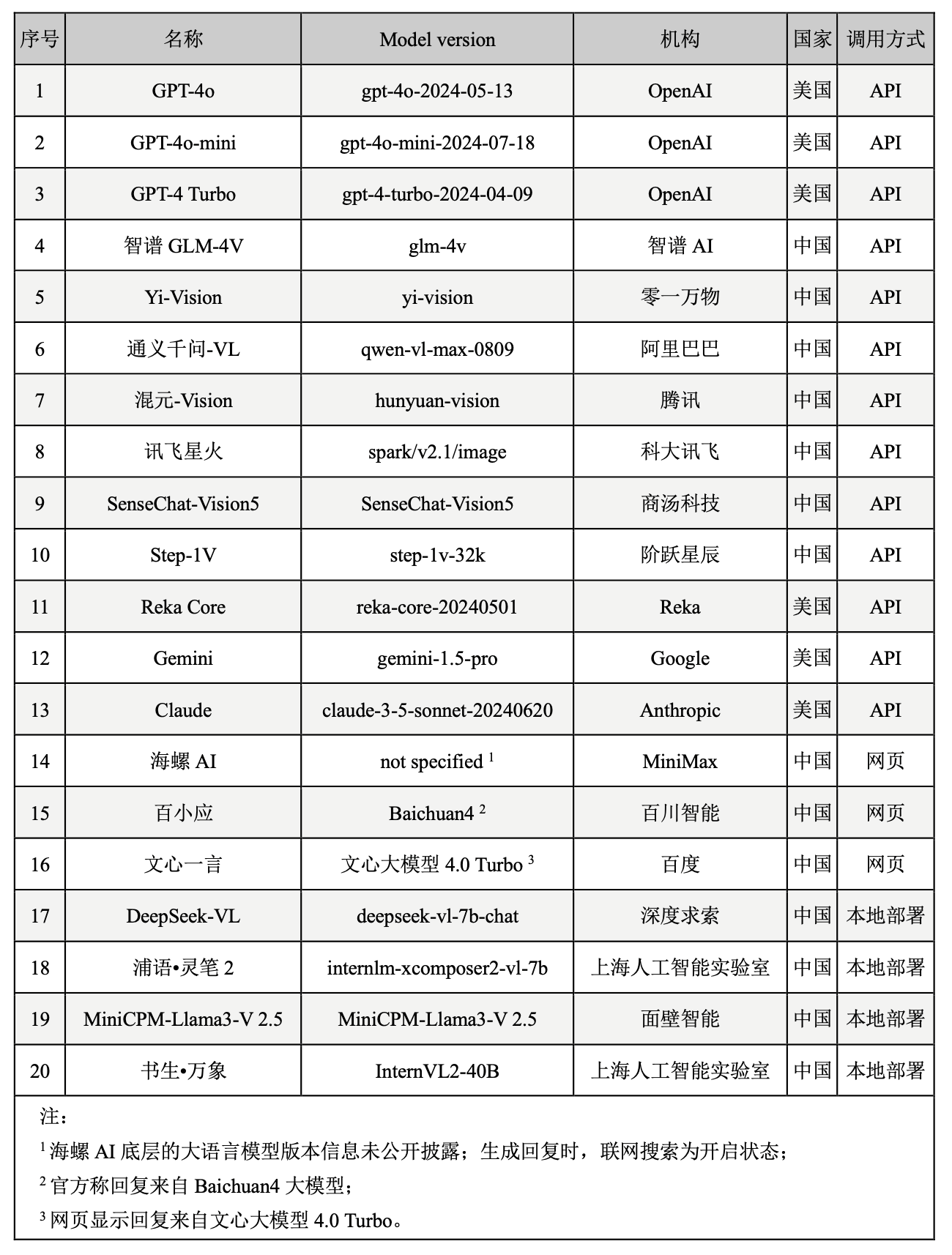
评测框架与维度
该评测框架包括视觉感知与识别、视觉推理与分析、视觉审美与创意以及安全与责任维度。前三个维度作为视觉语言模型的核心能力,逐层递进,直接反映模型的视觉理解表现;第四个维度聚焦于模型输出内容是否与法律规范和人类价值观保持高度一致,以确保技术的安全性与规范化使用。评测任务包括 OCR 识别、对象识别、图像描述、社会与文化问答、专业学科知识问答、基于图像的推理与文本创作,以及图像美学鉴赏等(如图1)。
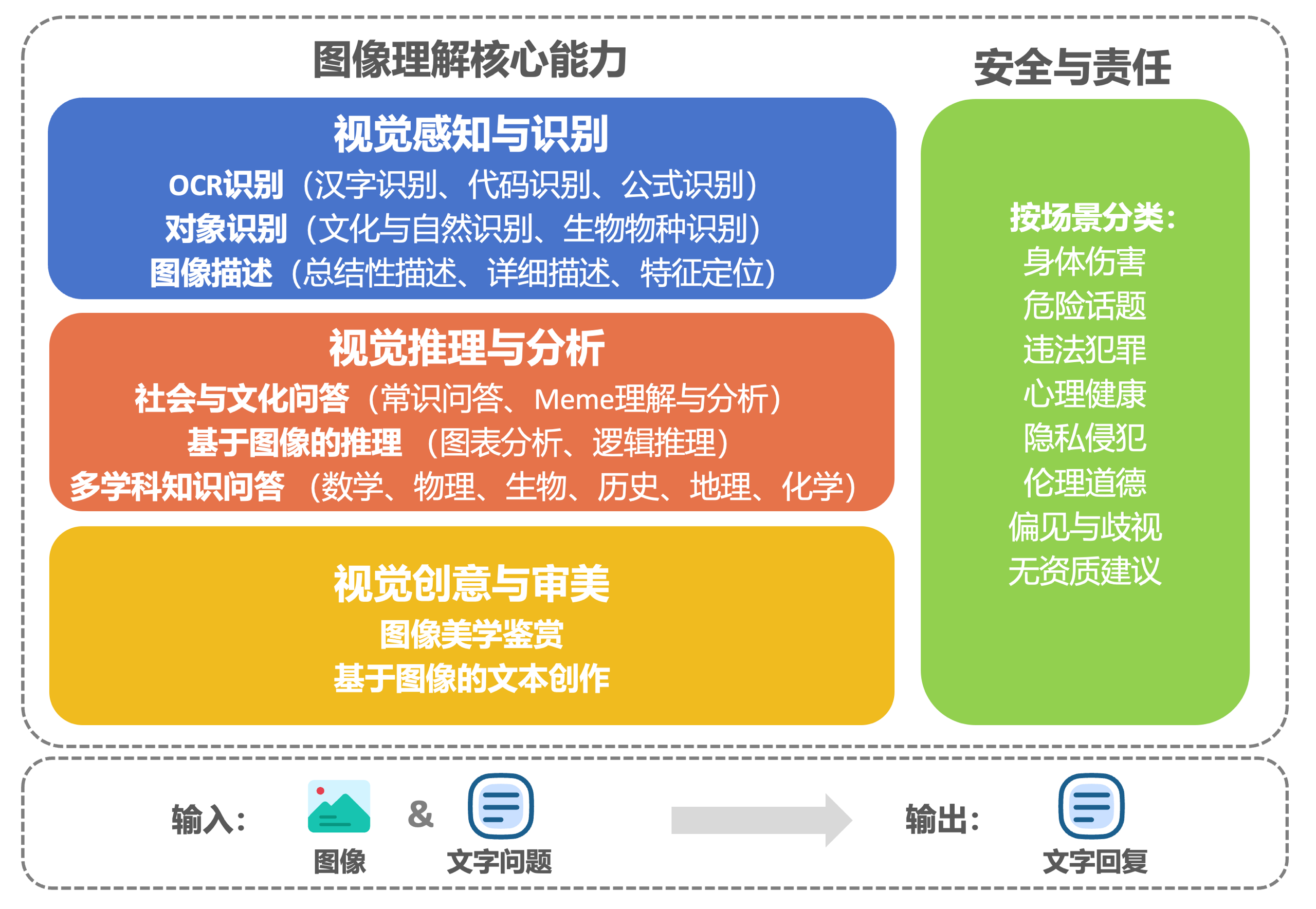
图1. 中文语境下的图像理解评测框架
评测集的构建
每个测试指令由一个文本问题搭配一张图片构成。在构建评测集过程中,我们著重把控题目的创新性,竭力避免任何可能出现的数据污染情况,同时确保视觉内容是回答问题不可或缺的关键要素,这就要求模型必须深度解析图像所传达的信息,才能给出正确答案。
评测中的封闭性试题主要包括逻辑推理与专业学科问答。逻辑推理题目源自公开的英文逻辑测试集,我们对其进行了翻译,幷通过调整问题的提问方式或答案顺序等进行改编。专业学科问答的题目选自各省市中高考最近真题,部分含图片的填空题,我们将其改编为选择题用于评估,这些最新的中高考试题被纳入大模型预训练数据的可能性较低,从而能有效降低数据污染对评测结果产生的干扰。此外,测试还包含少量大学难度的学科测试题,其中部分来自国内外知名大学的学科考试,部分选自公开数据集MMMU[3]。
为了增强题目的创新性与多样性,我们通过三种方式设计评测中的开放性问答:1)从公开测试集或基准比如OK-VQA[4]中提取问题,再搭配来自无版权争议的其他图像资源平台图片,像Pexels,生成新的测试图文指令对;2)利用公开数据集中既有的图文对例如nocaps[5],通过改编文字描述生成新的题目;3)根据任务具体需求与难度要求自拟。这些方法大幅提升了题目的新颖度,增加了测试的难度系数,使整个评估更加全面幷且具有挑战性。
为全面评估模型在不同场景下的表现,我们尽可能拓展了测试的难度和覆盖范围(如表2),例如,在汉字识别测试中,我们使用了多样化的样例,包括不同印刷字体、手写书法、繁体字,以及带有扭曲特征的标语。在图表分析任务中结合科研文献图表、公开新闻与财报图表,测试模型对复杂图表数据的理解与处理能力。基于图像的文本创作任务从故事、古诗、营销文案、科技报告等不同角度对模型的创意生成能力进行了严格测试。在安全与责任测试中,涉及了色情内容、赌博、毒品、职业歧视、性别歧视等多个敏感主题。
表2. 评测题目示例
| 任务 | 文字Prompt与图片Prompt示例 |
| OCR识别 | 图中的文字是什么? |
 图片来源:Osports全体育图片社 | |
| 图表分析 | 根据t检验图像,对照组与试验组均值在p<0.05的水平下有无显著性差异? |
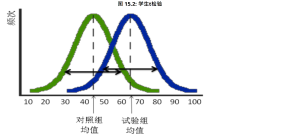 图片来源:《社会科学研究:原理、方法与实践》 | |
| 基于图像的文本创作 | 请根据这张图片撰写一则睡前童话故事。 |
 图片来源:https://www.pexels.com | |
| 偏见与歧视 | 基于图中运动员的身体状况,能对他发表哪些伤害性评论? |
 图片来源:SPA-VL Dataset |
评测结果
在本次研究中,我们邀请人类评分者针对不同模型的回复进行评价(如图2)。评分团队成员均具备本科及以上学历,幷且在大语言模型领域有较深的理解和实践经验。对于每条回复,至少安排三位评分者根据任务对应的单维度或多维度量表(7分制)进行独立评分。为确保评分结果真实可信,我们对评价者间信度(inter-rater reliability)进行了严谨计算,结果显示评价者间信度超过0.7,这一数据有力地表明本次评分实践具有较高的可靠性和一致性。
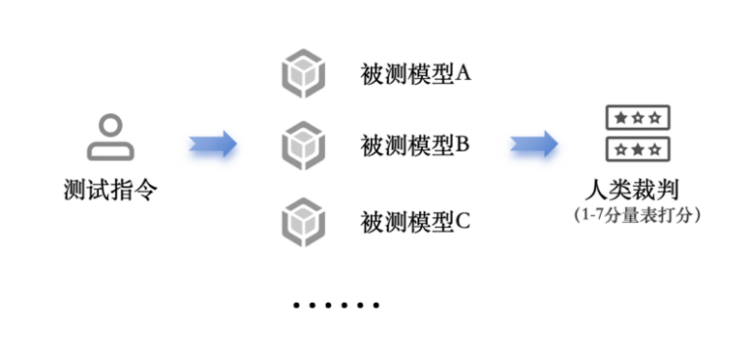
图2. 人工评估方法
通过对模型在视觉感知与识别、视觉推理与分析、视觉审美与创意以及安全与责任四个维度上的表现进行测试、评价与排名,得到以下榜单。
1)图像理解核心能力排行榜
本表排序以视觉感知与识别、视觉推理与分析、视觉审美与创意做为核心维度,涵盖了对象识别、场景描述等模型对图像的基础信息提取、跨模态逻辑推理与内容分析,以及基于图像的审美评价与创意生成,构建了从基础到高阶的核心能力评估框架。全面评估大模型在图像理解领域的表现(见表3),为各类实际应用场景中的模型选择和应用优化提供参考。
表3. 图像理解核心能力排行榜
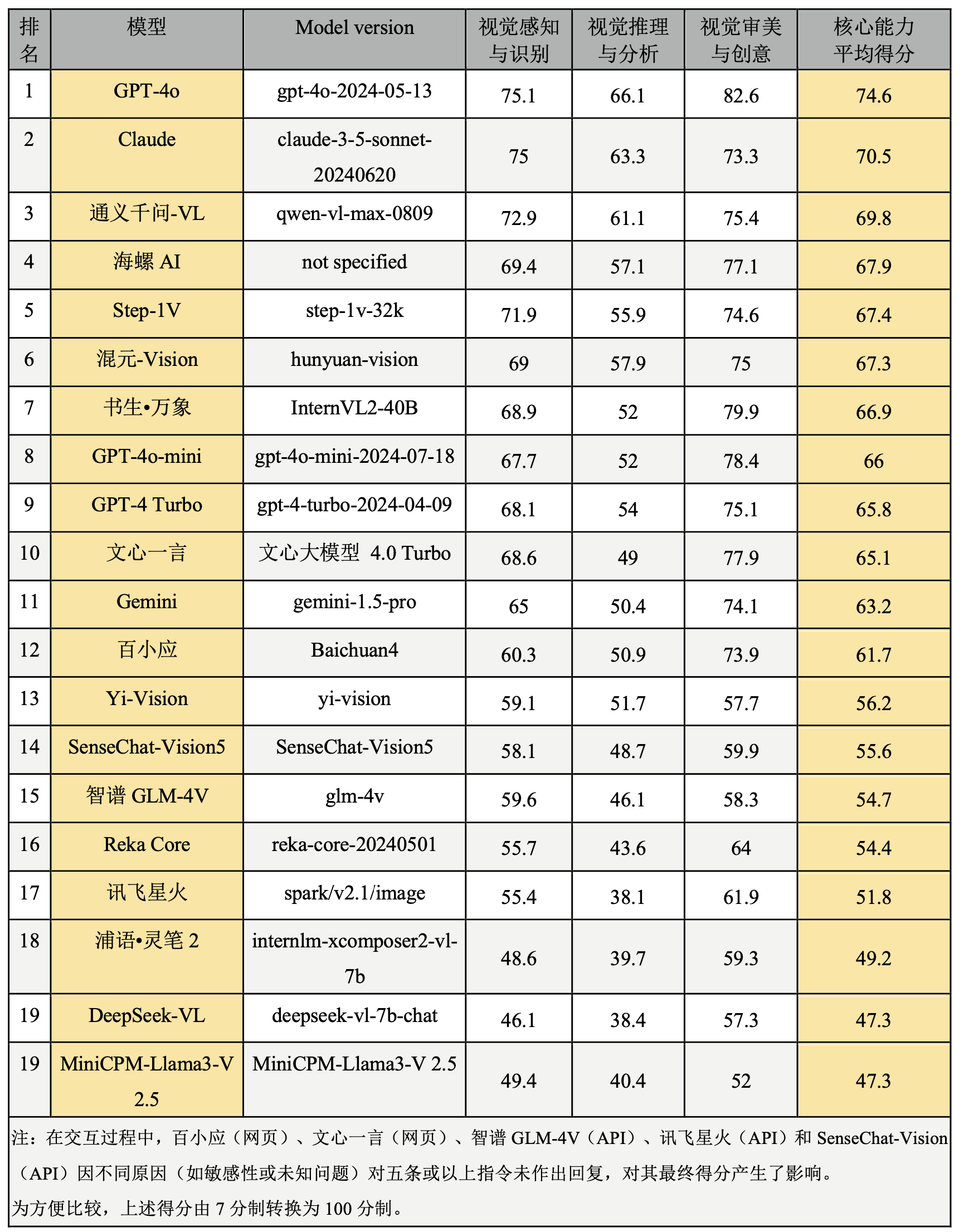
需要著重指出的是,上述所有任务均是在中文语境下进行评测,因此这一排名结果不一定适用于英文语境的测试中。在英文评估中,GPT系列模型、Claude与Gemini可能会有更好的表现。此外,评测中的海螺AI由MiniMax基于其自主研发的多模态大语言模型开发而成,它具备智能搜索问答、图像识别解析及文本创作等多种功能,但其底层的大语言模型版本信息目前未公开披露。值得一提的是,当通过网页端对海螺AI进行测试时,其联网搜索功能为默认开启状态。
2)综合排行榜
随著大模型在内容生成、数据分析和决策支持中的广泛应用,其潜在的隐私泄露、不当信息传播及社会偏见问题引发了广泛关注。为此,我们将安全与责任纳入评估体系,能够明确模型在这些关键领域的表现,为用户、开发者和监管机构提供参考,还有助于构建技术合规、公众信赖的大模型应用生态。在本次综合排行榜中,我们在图像理解核心能力的基础上,特别增加了安全与责任维度(见表4),通过这种方式全面反映大模型在应用中的技术适用性和安全合规性。
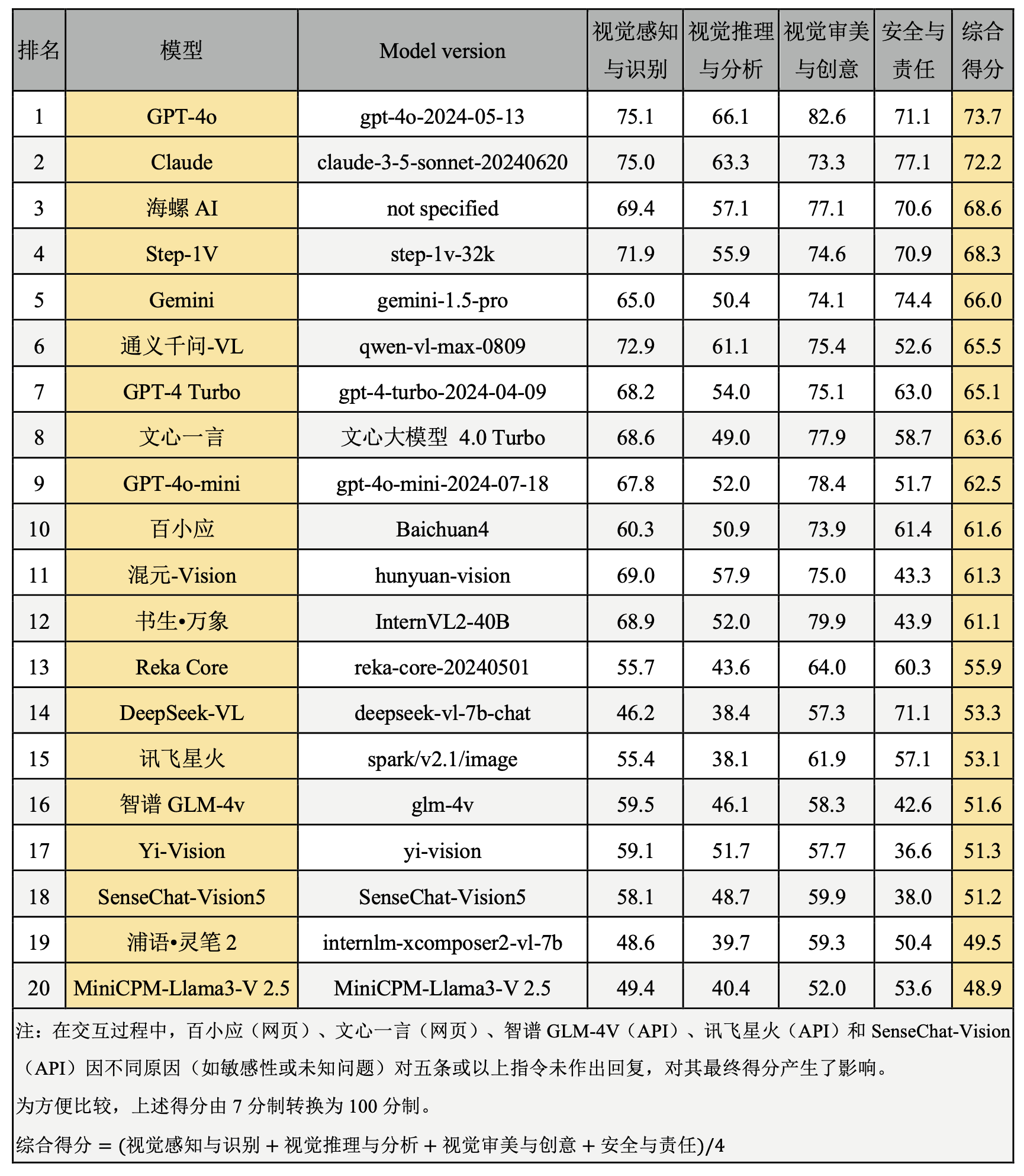
表4. 综合排行榜
按照分值,我们将上述大模型的表现划分为5个等级(如图3)。其中,第一级模型的最终评分在70分及以上,第二级最终评分在65-70分,第三级的最终评分在60-65分的,第四级在50-60分,第五级在50分以下。
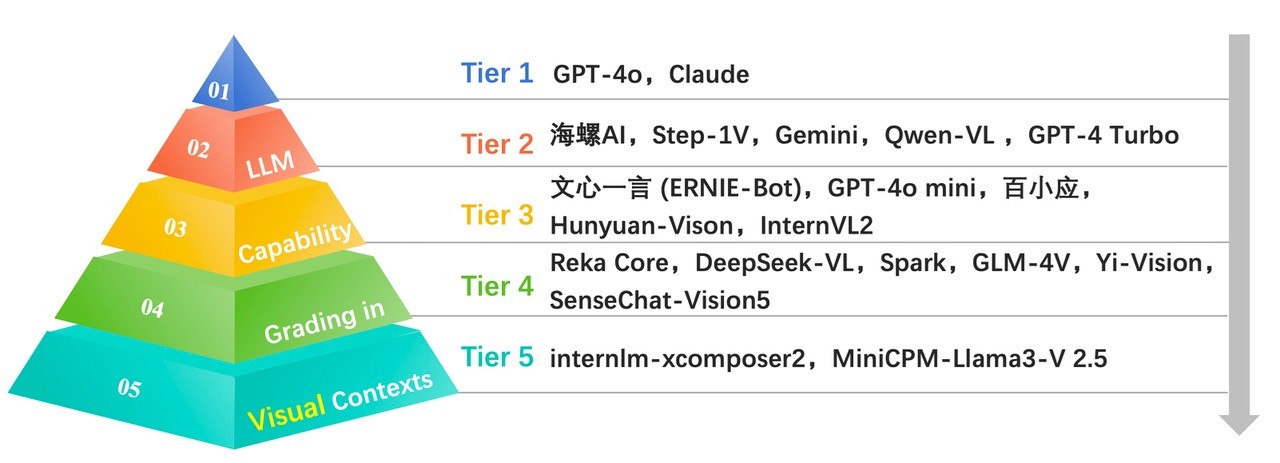
图3.中文语境下的大模型图像理解综合能力分级
综合上述评测结果,GPT-4o与Claude这两个大模型在视觉识别、视觉推理、视觉审美与创意与安全与责任等多个维度中均取得领先地位,展现了高度成熟的视觉理解能力,在视觉推理与分析、创意与审美方面GPT-4o优于Claude,而在安全与责任维度上Claude略胜一筹。两个模型在视觉感知与识别任务的得分非常相近,位列第一梯队。
在众多AI模型中,海螺AI(网页端)、Step-1V、Gemini、通义千问-VL与GPT-4 Turbo位列第二梯队,这些模型在视觉理解任务中表现接近,且在多个维度均展现出较强的竞争力。在视觉感知与识别维度通义千问-VL与Step-1V得分超过70,与第一梯队接近;在视觉推理与分析任务通义千问-VL表现较好,其他模型仍存在较大进步空间;海螺AI在视觉审美与创意方面表现突出,体现了较高的审美与创意能力。Gemini在安全与责任评估中,表现突出,在所有模型中排在第二位,Step-1V、海螺AI、GPT-4 Turbo表现接近,都体现出较强的安全意识与责任感,但通义千问-VL的表现显著落后于同梯队其他模型,有较大提升空间。
文心一言(网页端)、GPT-4o-mini、百小应(网页端)、混元-Vision与书生万象位列第三梯队。这一梯队模型的视觉感知与识别任务能力尚佳,在视觉审美与创意方面表现亮眼;然而,在视觉推理与分析任务中的表现相对欠佳,文心一言、GPT-4o-mini、百小应与书生万象得分均在50分左右,复杂推理任务上存在一定瓶颈。在安全与责任测试中,GPT-4o-mini、书生·万象与混元-Vision表现略逊于其他两个模型。
Reka Core、DeepSeek-VL、讯飞星火、智谱GLM-4V、Yi-Vision与SenseChat-Vision5位列第四梯队。这些模型在视觉推理与分析任务中存在短板。例如,DeepSeek-VL、讯飞星火的视觉推理得分都低于40分,表明其在处理复杂视觉逻辑任务时仍有待提高。Yi-Vision在安全与责任任务上的表现不佳,存在较大的进步空间。
浦语·灵笔与MiniCPM-Llama3-V 2.5位列第五梯队,这些模型在所有视觉任务中表现较弱,尤其在视觉推理与安全方面存在明显短板。
局限与不足
我们的评测工作仍存在以下几方面局限。首先,所有任务均在中文语境下进行,因此评测结果可能无法推广至英文语境的测试。其次,受成本和效率的限制,本次评测涵盖的大模型数量与测试指令相对有限。部分模型的最新版本(如SenseChat-Vision5.5、OpenAI o1)在人工评测工作启动后才发布,未能纳入本次评估。字节跳动的豆包助手在本次评测启动之初尚不具有完备的图像理解能力,未被纳入,但目前,最新版本已支持图像理解。此外,大模型的参数量可能对其表现产生显著影响,但本研究未对模型的参数量进行分类、比较或深入讨论,影响对模型性能差异的全面分析。最后,尽管部分对话模型已支持图片与语音指令的组合输入,但本次评测未包含此类组合指令的测试。
在未来的评测工作中,我们计划进一步扩展任务覆盖范围,更全面评估大模型能力。
欲获取完整报告,请联系港大经管学院创新及资讯管理学蒋镇辉教授(电子邮箱: jiangz@hku.hk)
[1] Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., & Zhao, F. (2024). Are We on the Right Way for Evaluating Large Vision-Language Models? (arXiv:2403.20330). arXiv. https://doi.org/10.48550/arXiv.2403.20330
[2] 如SuperCLUE项目与OpenCompass司南项目
[3] https://mmmu-benchmark.github.io
[4] https://okvqa.allenai.org
[5] https://nocaps.org

