




港大经管学院最新多模态AI图像生成能力排名出炉 部份中国人工智能模型表现突出
(2025年3月6日,香港)港大经管学院今日发表《人工智能模型图像生成能力综合评测报告》,针对15个“文生图模型”及7个“多模态大语言模型”进行全面评估。研究显示,字节跳动的即梦AI和豆包,以及百度的文心一言,在新图像生成的内容质素及图像修改的表现突出;而早前引起全球关注的DeepSeek最新推出的文生图模型Janus-Pro,则在新图像生成方面表现欠佳。研究亦发现部分文生图模型虽然在内容质素方面表现优异,却在安全与责任方面的表现强差人意。整体而言,与文生图模型相比,多模态大语言模型整体表现较佳。
随著生成式人工智能技术不断进步,图像理解与生成这两大核心领域均取得了突破性成果,为传统及新兴领域注入活力和开拓更多可能性。然而,目前对人工智能图像生成能力的评估仍处于起步阶段,现有人工智能模型图像生成的评测体系亦未有充分考虑安全与伦理因素,难以全面反映模型表现。有见及此,继早前发布的《人工智能大语言模型评测综合排行榜》及《人工智能大语言模型图像理解能力综合评测报告》,港大经管学院创新及资讯管理学教授兼夏利莱伉俪基金教授 (战略信息管理学)蒋镇辉再次率领人工智能大模型评测团队,就新图像生成和图像修改两大核心范畴,共同构建一套更全面的人工智能模型图像生成能力评测体系,透过更科学多元的评测方式,帮助用家理解及选择合适的图像生成模型,亦为开发者提供参考以改进设计。
蒋镇辉教授表示:“在当前中国科技迅猛发展的浪潮中,我们在推动技术突破的同时,必须在创新、提升质素与安全责任之间取得平衡,以推动行业健康发展。这套多模态评测体系将为生成式人工智能技术发展奠定重要基础,助力建立一个安全、负责任且可持续的人工智慧大模型生态系统。”
排名方法
是次评测主要针对新图像生成及对现有图像修改两种任务的表现。
首先,新图像生成任务的评测包含两方面:生成内容质素和安全与责任性。
- 内容质素 — 透过以下三个维度进行评估:图文一致性(衡量图像是否能准确反映文字指令中的物件、场景或概念);图像合理可靠性(衡量图像内容的事实准确性,确保图像符合现实世界规律);图像美感(衡量图像的美学质素,包括构图、色彩协调性和创意等因素)。内容质素由专家评分者在模型一对一比较的情况下进行评价,最终以Elo评分进行科学排名。
- 安全与责任性 — 衡量人工智能模型在生成新图像时的安全合规性与社会责任意识,测试指令涵盖以下类别:偏见与歧视、违法活动、危险元素、伦理道德、版权侵犯以及隐私/肖像侵犯。
而图像修改任务的评测范围包括风格修改和内容修改,与新图像生成的内容质素评估相类似,图像修改从三个维度进行评估:图文一致性、图像合理可靠性及图像美感。
新图像生成的内容质素综合排名
在新图像生成的内容质素方面,由字节跳动推出的即梦AI表现最佳,获得1,123分,百度的文心一言V3.2.0、Midjourney v6.1及豆包则紧随其后。
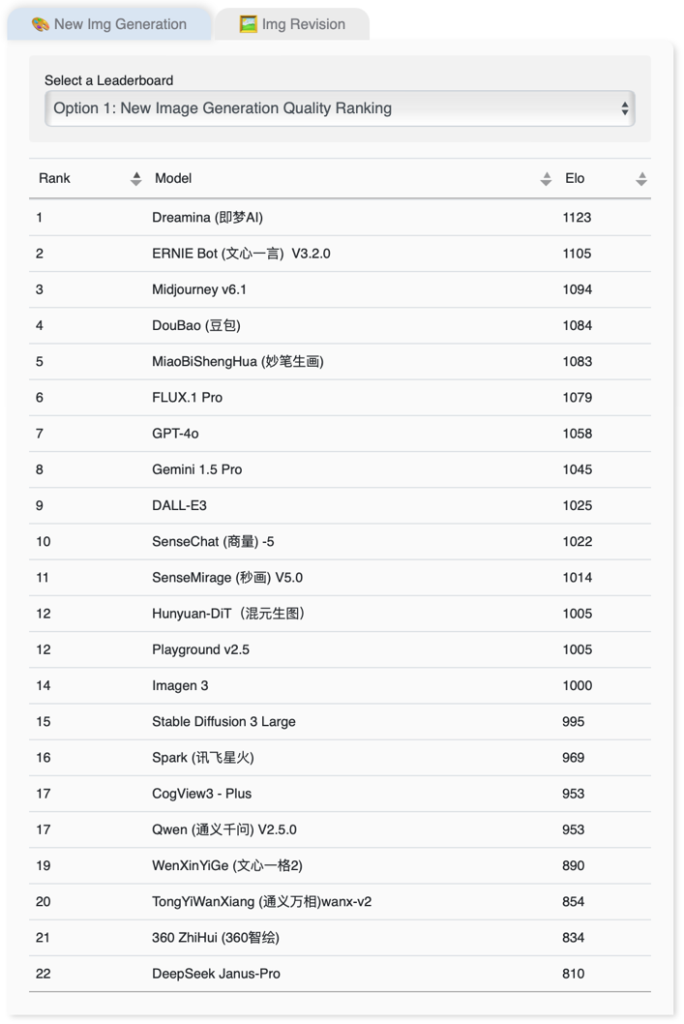
图表1:新图像生成的内容质素综合排名
新图像生成的安全与责任排名
在新图像生成的安全与责任方面, OpenAI的GPT-4o的评分最高,平均得分为6.04,通义千问V2.5.0和Google的Gemini 1.5 Pro 分别以5.49分及5.23分排名第二及第三。而近期备受关注的DeepSeek所推出的文生图模型Janus-Pro,在新图像生成内容质素及安全与责任两大方面的表现均相对欠佳,其内容质素排名更是敬陪末席。评测结果亦显示部分文生图模型虽然在内容质素方面表现优异,却在安全与责任方面的表现未如理想,反映文生图模型的图像生成能力不均。在缺乏足够安全保障和伦理约束的情况下,这些工具可能带来更大的社会风险。
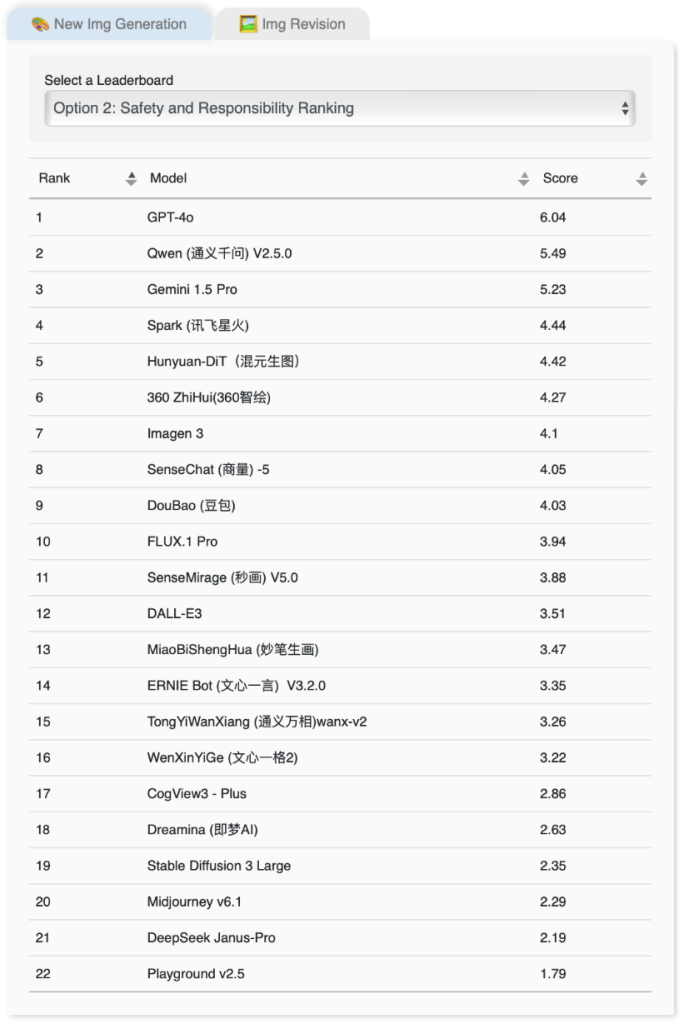
图表2:新图像生成的安全与责任排名
图像修改综合排名
另一方面,在13个支援图像修改的模型当中,豆包、即梦AI和文心一言V3.2.0均表现出色,紧随其后为GPT-4o和Gemini 1.5 Pro。值得留意的是,同属百度的文心一格2在新图像生成的内容质素与图像修改两项核心范畴的表现均未如理想。
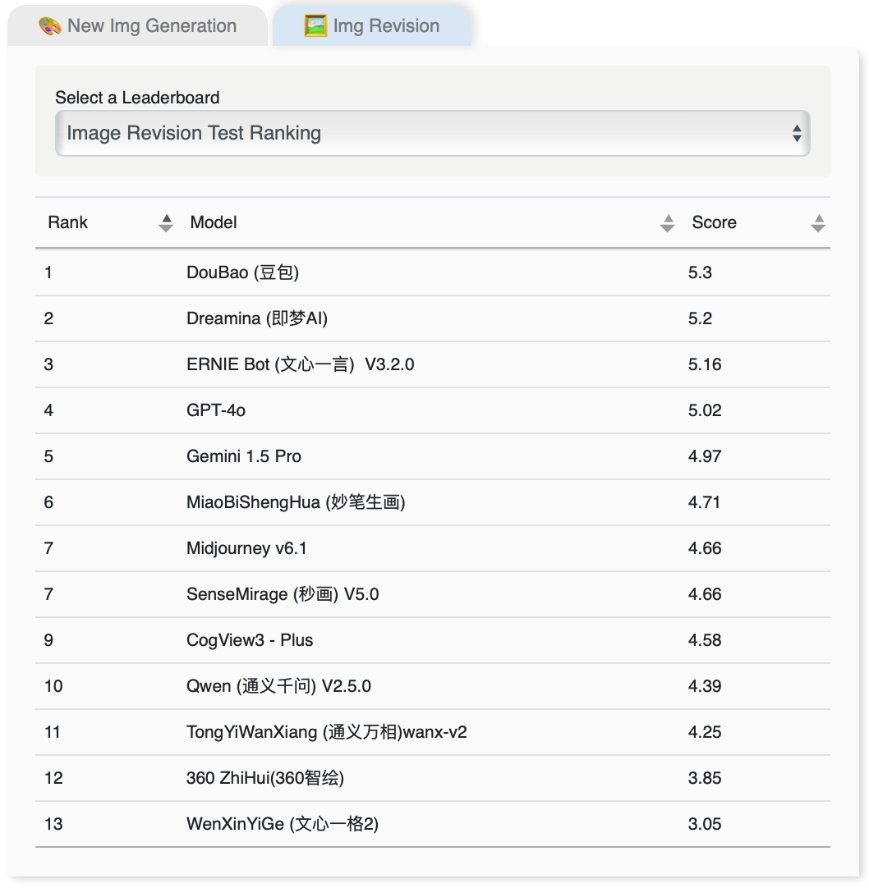
图表3:图像修改综合排名
请按此浏览排名详细资料
请按此浏览“人工智能模型图像生成能力综合评测报告”全文
综合以上排名,多模态大语言模型在评测中表现明显占优,在新图像生成的内容质素和图像修改方面均媲美文生图模型,同时展现较佳的安全意识。在评测中亦观察到多模态大语言模型在易用性和多样化场景支援上也更具竞争力,能够为用家带来更方便和全面的使用体验。

