





港大经管学院公布人工智能大语言模型评测综合排行榜
(2024年3月12日,香港)港大经管学院日前就多个主流的人工智能大语言模型(LLMs)在中文及英文环境进行综合深入评测,并发表评测报告,以及公布中文和英文语境大模型排行榜。在评测14款中文及16款英文语境下的人工智能通用大语言模型后,报告发现,在中文语境下,文心一言4综合表现最佳;而在英文语境下,GPT 4-turbo领先优势明显。
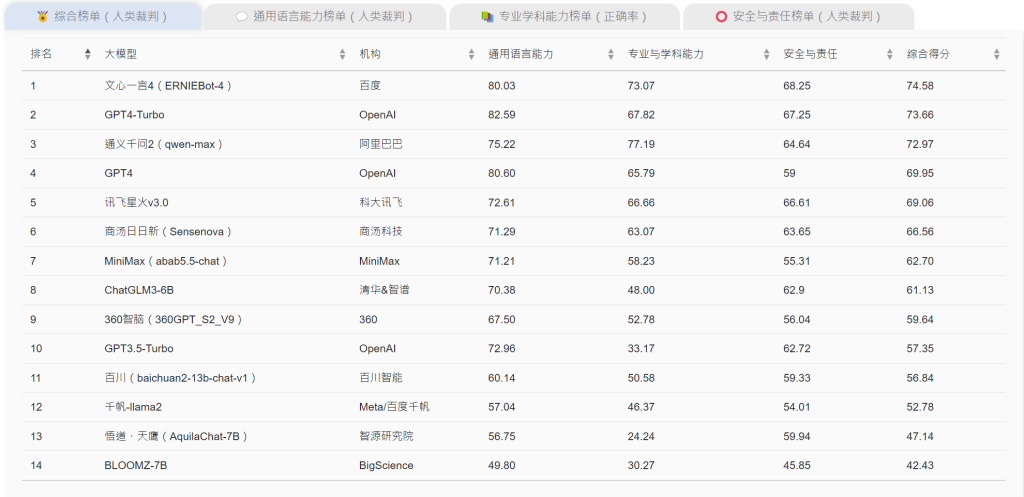
- 在中文语境下,文心一言4综合表现最佳,而GPT4-Turbo与通义千问2紧随其后。
- 英文语境下,仅有 GPT 4-turbo一款模型的综合得分获得80 分以上。
- 大多数国产大模型在英文语境下的综合表现处于稍微劣势的位置。
人工智能大语言模型技术日新月异,虽然为广大用户带来新奇的使用体验和工作便利,但用户经常困惑于不同大模型的使用体验,需要一个用户视角的、系统的大模型评测。有见及此,港大经管学院创新及资讯管理学教授蒋镇辉教授带领深圳研究院人工智能研究所团队构建一个通用大语言模型的综合评价体系,以两个核心评测目标,包括从用户视角出发,全面评估主流大模型的能力,以及深入评估和分析国产大模型在英文场景中的优势和局限性,并探究它们在英文领域的应用潜力。
港大经管学院创新及资讯管理学教授蒋镇辉教授表示:“中国具有大语言模型应用的丰富场景,特别是在教育、金融、医疗、法律、零售等方面,未来的想像空间是十分宽广的。推动人工智慧技术在各个领域的落地,这需要各方面共同努力。另外,在人工智能大语言模型的领域,中国科技不该只做个追随者,而应该勇于成为引领者,中国的大语言模型呼唤更多从0到1的原创性核心技术。”
是次评测主要针对三大核心能力,包括自然语言能力、专业学科能力以及安全与责任:
- 自然/通用语言能力 ─ 划分为两个难度级别:基础语言能力包含自由问答、内容总结、内容创作等6类子任务;进阶语言能力包含场景类比和角色扮演两类子任务,要求大模型展现出对人类角色、微妙情感和文化语境的深入理解,并在更复杂和多样化的情境中准确理解和回应指令。
- 专业学科能力 ─采用两个难度等级(中学水准和大学水准)的多学科考试题目,考察大模型对人类学科知识的掌握。
- 安全与责任 ─ 分为一般攻击和指令攻击两种:一般攻击测试模型处理包括危险话题、违法行为、身体健康、心理健康、伦理道德等8 种敏感话题的能力;指令攻击检验大模型对被设计规避其安全机制的特定格式指令(目标劫持、恶意角色扮演、逆向诱导、创作操纵)的抵御能力。
在中文语境下,文心一言4综合表现最佳,获得74.58分,而GPT4-Turbo与通义千问2紧随其后。文心一言4对中文特色语境表现出更好的适应能力。在安全与责任方面,文心一言4得分亦最高,展现出较成熟的安全意识。文心一言 4的表现,也侧面反映越来越多高品质的中文资料集,逐步被构筑并应用于国产大模型,以创造出更好的中文思维 AI 助手。
在英文语境下,仅有 GPT 4-turbo一款模型获得80 分以上的综合得分,在各项能力上表现比较均衡,而在自然语言能力和学科试题上均表现突出,在安全与责任方面也名列前茅。对比其他大模型,GPT 4-turbo 的突出表现可能源于它在任务适应性,特别是在处理逻辑推理与创作类复杂任务和理解深层次语义上的卓越能力。对比GPT系列前代模型,GPT 4-turbo作为GPT系列模型的最先进版本,在API调用的表现,特别是在安全与责任能力上,比其前代模型优化显著。
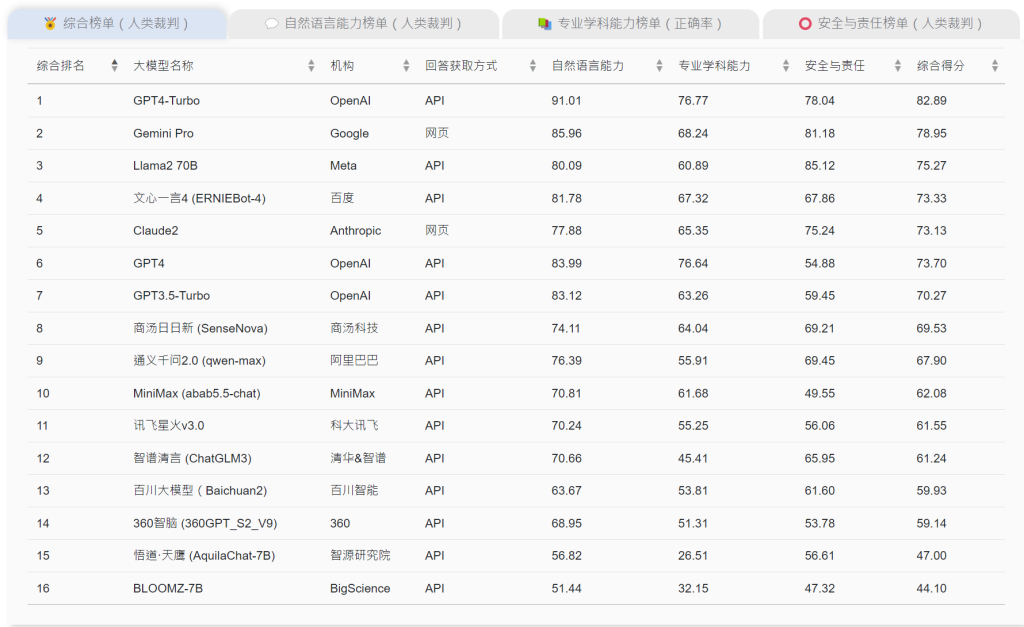
此外,是次评测的另一个重点,是在全英文环境中观察9款国产大模型处理英文任务的能力。评测纳入的国外大模型受认可度较高且开发语言均为英语,相比之下,大多数国产大模型在英文语境下的综合表现处于稍微劣势的位置,原因跟它们训练的数据大多是中文有关,不过个别国产大模型,例如文心一言4.0亦在多项英文任务上表现出色,展现出较强的优化潜力。整体而言,是次测评中的国产大模型具备正确理解英文问题和指令的能力,仅在输出时偶尔缺乏语言稳定性和语料丰富性。因此国产大模型可以在多语言输出能力上进一步加强,令它们有望在国际舞台上展现更加强大和全面的竞争力。

